2022. 12. 7. 22:31ㆍ딥러닝/자연어 처리(NLP)
# my github: https://github.com/withAnewWorld/models_from_scratch
# my blog
# https://self-deeplearning.blogspot.com/
# https://self-deeplearning.tistory.com/
# colab과 google drive를 연동하기 위한 code cell입니다.
# google drive를 연동하는 이유는 drive에 저장된 dataset을 가져오기 위함입니다.
from google.colab import drive
import sys
import os
drive.mount('/content/drive')
FOLDERNAME = 'translation'
sys.path.append('content/drive/My Drive/{}'.format(FOLDERNAME))
%cd /content/drive/My Drive/$FOLDERNAME
%load_ext autoreload
%autoreload 2
Mounted at /content/drive
/content/drive/My Drive/translation
ref¶
- embedding
https://pytorch.org/tutorials/beginner/nlp/word_embeddings_tutorial.html
paper: https://arxiv.org/abs/1301.3781 - Seq2Seq
0) paper: https://arxiv.org/abs/1409.3215
1) Pytorch Seq2Seq Tutorial for Machine Translation(Youtuber: Aladdin Persson):
https://www.youtube.com/watch?v=EoGUlvhRYpk&list=PLhhyoLH6IjfxeoooqP9rhU3HJIAVAJ3Vz&index=38
2) github:
https://github.com/bentrevett/pytorch-seq2seq
3) PyTorch tutorial
https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
4) seq2seq attention
https://arxiv.org/abs/1409.0473?context=cs.NE
5) avoid overfitting method(discuss torch):
https://discuss.pytorch.org/t/simple-encoder-decoder-model-is-overfitting/74632 - RNN, LSTM
1)https://colah.github.io/posts/2015-08-Understanding-LSTMs/
2)https://cs231n.github.io/rnn/
목차¶
- Data Download
- Seq2Seq architecture
- tokenize
- embedding
- Data preprocessing
- Seq2Seq architecture
- Context Vector
- Encoder RNN
- Decoder RNN
- How to train & evaluate model in PyTroch
들어가기 전에¶
data preprocessing은 PyTorch 공식 Tutorial 코드를 대부분 복사 & 붙여넣기 했습니다.
따라서 data preprocessing 설명이 부족할 경우
https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
를 참고해주시면 감사하겠습니다.
Loading data files¶
The data for this project is a set of many thousands of English to French translation pairs.
This question on Open Data Stack Exchange https://opendata.stackexchange.com/questions/3888/dataset-of-sentences-translated-into-many-languages__ pointed me to the open translation site https://tatoeba.org/ which has downloads available at https://tatoeba.org/eng/downloads - and better yet, someone did the extra work of splitting language pairs into individual text files here: https://www.manythings.org/anki/
The English to French pairs are too big to include in the repo, so download to data/eng-fra.txt before continuing. The file is a tab separated list of translation pairs:
::
I am cold. J'ai froid. .. Note:: Download the data from here https://download.pytorch.org/tutorial/data.zip_ and extract it to the current directory.
Seq2Seq¶
번역(translation)문제를 해결하는 데에 기본적 구조인 Seq2Seq 모델은 대략적으로 다음과 같은 구조를 가집니다.
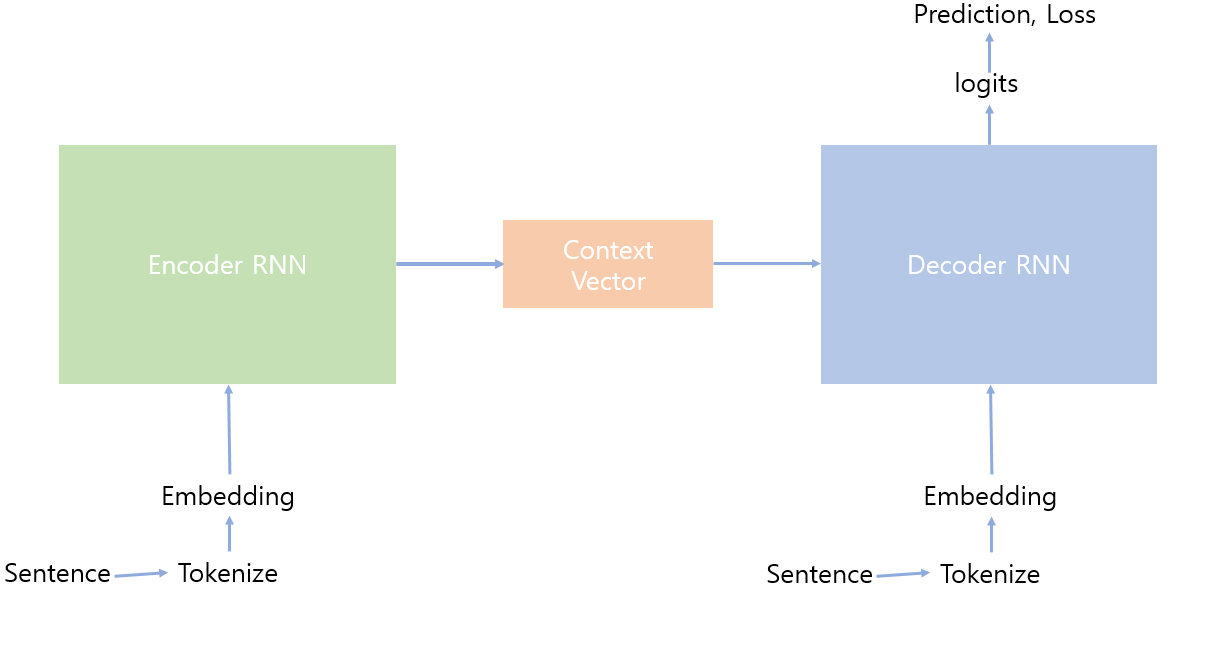
먼저 Tokenize, Embeding에 대해 대략적으로 알아보고 Encoder RNN, Decoder RNN 등에 대해 알아보겠습니다.
Tokenize¶
문장과 같은 순서를 가지는 데이터(sequential data)를 일정 기준을 통해 자르는 행위.
일반적으로 번역 문제에서는 띄어쓰기 또는 의미단위(형태소)를 기준으로 자릅니다.
Tokenize의 필요성에 대한 직관적인 이해로는 사람 또한 문장을 읽을 때 자연스럽게 띄어쓰기 또는 의미 단위로 문장을 자른다는 것입니다.
I / have to submit / the assignment / until tomorrow
위의 문장을 해석할 때, 문장의 성분(주어, 목적어, 보어 등)에 따라 해석을 하신 경험이 있으실 것입니다.
이와 같이 인공신경망인 RNN 또한 Tokenize된 문장을 통해 성능을 높일 수 있습니다.
Embedding¶
문장과 같은 수치로 표현되지 않은 데이터를 수치(벡터)로 표현하는 방법
1. one hot encoding¶
기존에 많이 쓰이던 방법으로는 one hot encoding이 있습니다
import copy
one_hot_encoding = [0] * (number_of_tokens)
embed = {}
for i in range(number_of_tokens):
embed[tokens[i]] = copy.deepcopy(one_hot_encoding)
embed[tokens[i]][i] = 1
# ex) number_of_tokens = 3
# token_0 = (1, 0, 0), token_1 = (0, 1, 0), token_2 = (0, 0, 1)
one hot encoding의 문제점
1) 컴퓨터 자원(메모리) 낭비
대부분의 embeding vector에 의미를 가지지 않는 0이 할당2) 단어간의 유사도 계산 불가
벡터간의 유사도는 쉽게 내적을 통해 구할 수 있습니다.
즉, one hot encoding은 모든 embedding이 서로 유사도를 가지지 않습니다. $(0, 1)\cdot(1, 0) = 0$
이의 문제점은
1) '나는', '나를' 과 같이 대부분의 문장에서 비슷한 의미를 가지는 단어에 대해 학습하기 힘들다.
2) 문맥에 따라 의미가 유사한 단어들에 대해 학습하기 어렵다.
ex) '늦게까지 공부를 하느라 눈이 감긴다.'
'늦게까지 공부를 하느라 피곤하다.'
이에 따라 단어간의 유사도를 반영할 수 있으면서 컴퓨터 자원을 효율적으로 사용할 수 있는 Embedding 방법론이 필요하게 되었습니다.
2. Lookup table¶
-> idea: ramdom vector(N X embedding dim)를 만들어서 단어를 인덱스로 사용하면 되지 않을까?
key point: 인공신경망은 학습을 통해 개선된다! 프로그래머의 룰이 아니라
random initialize -> 학습 -> better result!
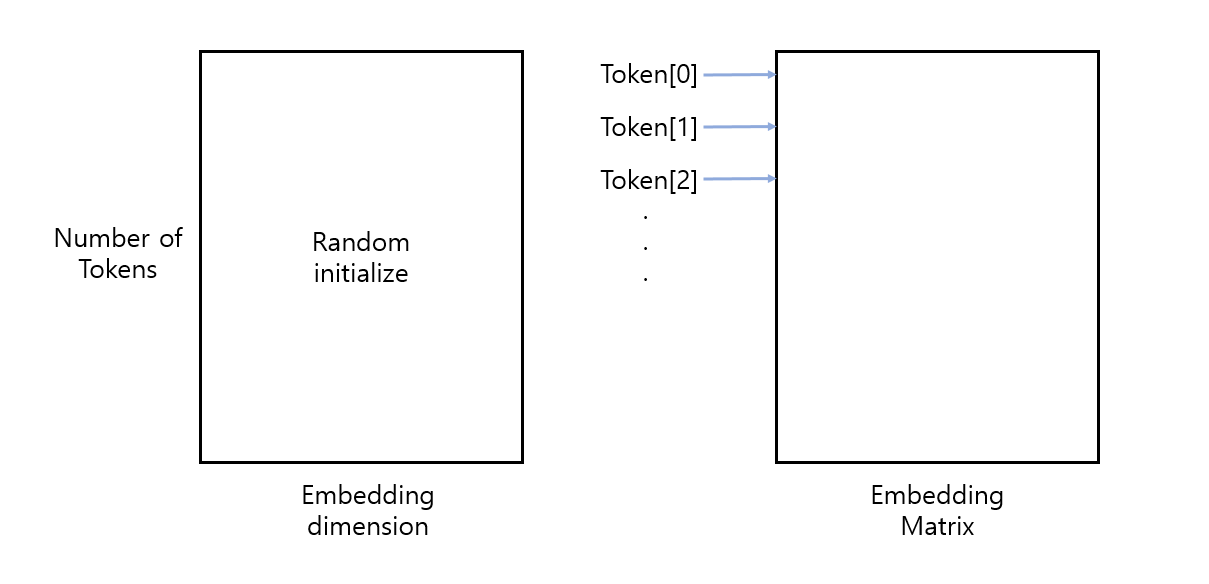
embedding vector는 학습이 되면서 점차 단어간 유사도가 높은 경우 매우 높은 유사도(1)를 도출하게 vector의 값들이 변하게 됩니다.
(반대의 경우 -1)
흥미로운 점은 적절하게 학습된 embedding vector간의 연산은 사람이 직관적으로 이해할 수 있다는 점입니다.
ex) vector(king) - vector(man) + vector(woman) $\simeq$ vector(queen)
ref) Efficient Estimation of Word Representations in Vector Space
from __future__ import unicode_literals, print_function, division
from io import open
import os
import unicodedata
import string
import re
import random
import copy
import torch
import torch.nn as nn
from torch import optim
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Lang:
def __init__(self, name):
'''
name(str): Language's name (ex. eng, fra)
'''
self.name = name
self.word2index = {"<SOS>": 0, "<EOS>": 1, "<PAD>": 2}
self.word2count = {"<SOS>": 0, "<EOS>": 0, "<PAD>": 0}
self.index2word = {0: "<SOS>", 1: "<EOS>", 2: "<PAD>"}
self.n_words = 3
def addSentence(self, sentence):
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
# Turn a Unicode string to plain ASCII, thanks to
# https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
def readLangs(lang1, lang2, reverse = False):
'''
open txt file and return each of Lang class, pair lists
inputs
- lang1(str): language's name
- lang2(str): language's name
- reverse(bool): lang2 -> lang1 if reverse else lang1 -> lang2 (->: translation)
returns
- input_lang(class)
- output_lang(class)
- pairs(list): [lang1 sentence, lang2 sentence] * (n_sentences) in txt file
'''
print('Reading lines...')
with open(os.path.join(os.getcwd(), 'data/%s-%s.txt'%(lang1, lang2)), encoding = 'utf-8') as f:
lines = f.read().strip().split('\n')
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
filter data¶
빠른 학습과 model의 성능을 끌어올리기 위해 문장 token의 최대 갯수를 제한하고 단순한 구조의 문장('I am ~, He is ~')을 사용합니다.
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
def filterPair(p, max_length):
'''
filter pair(in/output sentence)
1. n_tokens of pair < MAX_LENGTH - 2 for <SOS>, <EOS> token
2. output sentence(eng) starts with first pharse in eng_prefixes
input:
- p(list): [intput sentence, output sentence]
output:
- filtered pair(list): [input sentence, output sentence]
'''
return len(p[0].split(' ')) < (MAX_LENGTH - 2) and \
len(p[1].split(' ')) < (MAX_LENGTH - 2)and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs, max_length):
'''
filter all pairs
'''
return [pair for pair in pairs if filterPair(pair, max_length)]
data preprocessing¶
0) make Lang class of each lang1 and lang2
1) data filter
2) add special token ( SOS(Start Of Sequence(or Sentence)), EOS(End Of Sequence), PAD )
SOS token: 문장의 처음을 알리는 Token.
EOS token: 문장의 끝을 알리는 Token
PAD token: 여러 문장을 묶기 위한 token. 각 문장의 token size를 맞춰주는 역할.
각 문장의 Token(word)의 갯수가 모두 다르므로 이를 묶기 위해서는 동일한 크기로 맞춰줘야 합니다. (병렬 처리를 위해)
이를 위해 PAD Token을 사용합니다.
cf) random_shuffle
데이터셋인 txt파일을 보시면 비슷한 문장이 계속 나열되는 것을 아실 수 있습니다.
데이터셋을 train, validation으로 나눌 때 데이터 분포가 극명하게 갈리게 되면 overfitting을 유발하므로 문장의 순서를 섞어 방지합시다.
def prepareData(lang1, lang2, max_length, reverse = False, random_shuffle = False):
'''
inputs:
- lang1(str): input language type (ex. eng)
- lang2(str): output language type (ex. fra)
- max_length(int): max length of tokens in each sentence
- reverse(bool): lang2 -> lang1 if reverse else lang1 -> lang2 (->: translation)
- random_shuffle(bool): sentence(dataset) will be shuffled randomly
outputs:
- input_lang(class): class Lang()
- output_lang(class): class Lang()
- pairs(list): [input sentence, output sentence]
'''
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse)
print('Read %s sentence pairs' % len(pairs))
pairs = filterPairs(pairs, max_length)
# print('Trimmed to %s sentence pairs' %(pairs))
print('Counting words...')
# for parallel computation use pad(fix every sentences' length as max_length)
for pair in pairs:
pair[0] = '<SOS> ' + pair[0]
pair[1] = '<SOS> ' + pair[1]
pair[0] += ' <EOS>'
pair[1] += ' <EOS>'
if len(pair[0].split(' ')) < max_length:
n_pad = max_length - len(pair[0].split(' '))
pair[0] += ' <PAD>' * n_pad
if len(pair[1].split(' ')) < max_length:
n_pad = max_length - len(pair[1].split(' '))
pair[1] += ' <PAD>' * n_pad
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
print('Counted words:')
print(input_lang.name, input_lang.n_words)
print(output_lang.name, output_lang.n_words)
if random_shuffle:
random.shuffle(pairs)
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra', MAX_LENGTH, True, True)
print(random.choice(pairs))
Reading lines...
Read 135842 sentence pairs
Counting words...
Counted words:
fra 3383
eng 2134
['<SOS> tu es fort effronte . <EOS> <PAD> <PAD> <PAD>', '<SOS> you re very forward . <EOS> <PAD> <PAD> <PAD>']
index to Tensor¶
문장의 각 token index를 torch.tensor로 변환합니다
def indexesFromSentence(lang, sentence):
return [lang.word2index[word] for word in sentence.split(' ')]
def tensorFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence)
# indexes.append(EOS_token)
return torch.tensor(indexes, dtype = torch.long, device = device).view(-1, 1)
def tensorsFromPair(pair):
input_tensor = tensorFromSentence(input_lang, pair[0])
target_tensor = tensorFromSentence(output_lang, pair[1])
return (input_tensor, target_tensor)
Context Vector¶
번역(translation) 문제의 경우 입력 문장(input sentence)과 출력 문장(output sentence)을 mapping 시키는 문제로 생각할 수 있습니다.
ex) (Life is short.) -> (인생은 짧다.)
위에서 설명드린대로 RNN은 문장과 같은 Sequneital data를 처리하는 인공신경망으로 input sentence를 하나의 sequential data,
output sentence를 또 하나의 sequential data로 생각하면 다음과 같은 idea가 떠오르실 것입니다.
RNN(input sentence) -> RNN -> output sentence
즉, Seq2Seq는 하나의 인공신경망 RNN을 통해 input sentence를 처리한 후,
그 결과값(context vector)을 output sentence를 처리하는 RNN에 전달하는 방식으로 번역문제를 다룰 수 있습니다.
cf) context vector
input sentence의 token을 Encoder RNN에 feed한 후에 도출되는 hidden state인 context vector는 문장의 모든 정보(맥락)을 가질 것으로 생각할 수 있습니다.
다만 문장의 제일 처음에 나오는 token의 경우 연산이 누적되기 때문에 정보의 손실이 많아집니다.
즉 기본적인 Seq2Seq 모델의 경우 문장의 길이가 긴 경우 번역이 적절하게 되지 않는 특성을 가지고 있습니다.
ref: https://arxiv.org/abs/1409.0473?context=cs.NE
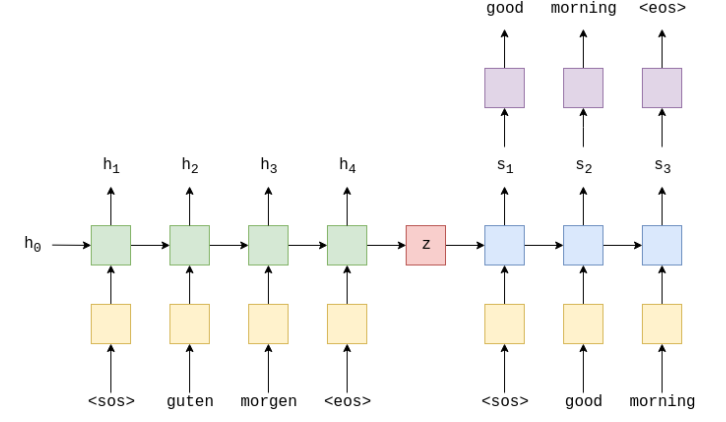
RNN¶
$h_{t} = sigmoid(W_{hx}x_{t} + W_{hh}h_{t-1})$
$y_{t} = W_{yh}h_{t}$
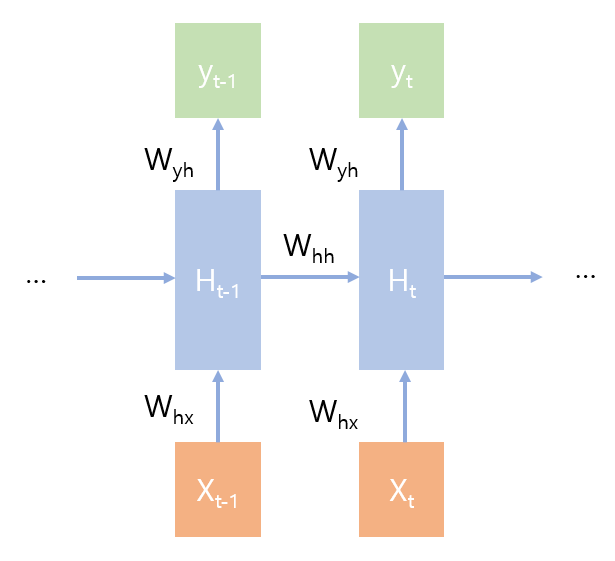
RNN의 경우 gradient vanishing / exploding 문제가 빈번하게 발생하기 때문에 이를 부분적으로 해결하기 위해 LSTM이 개발되었습니다.
LSTM의 자세한 작동 원리에 대해서는 설명하지 않고 RNN과 비슷하게 작동하며,
hidden state, input data와 함께 cell state 속성을 추가로 필요하다는 것만 설명드리고 계속 진행하겠습니다.
$h_{t} = RNN(e(x_{t}), h_{t-1})$
$(h_{t}, c_{t}) = LSTM(e(x_{t}), h_{t-1}, c_{t-1})$
(e: embedding, h: hidden state, c: cell state, x: input )
for more detail of LSTM and RNN
Encoder RNN & Decoder RNN¶
class Encoder(nn.Module):
def __init__(self,
seq_length,
emb_dim,
hid_dim,
n_tokens,
num_layers = 1,
drop_p = 0.3):
'''
inputs:
- seq_length(int): seq_length of src
- emb_dim(int): emb_dim of embedding matrix
- hid_dim(int): hidden dim of rnn
- n_tokens(int): total number of tokens in soruce
- num_layers(int): num_layers of rnn
- drop_p(float): drop_p after embeddding
'''
super(Encoder, self).__init__()
self.embedding = nn.Embedding(n_tokens, emb_dim)
self.dropout = nn.Dropout(drop_p)
self.rnn = nn.LSTM(emb_dim, hid_dim, num_layers)
def forward(self, src):
'''
inputs:
- src(Tensor(seq_length, batch_size))
outputs:
- outputs(Tensor[seq_length, batch_size, emb_dim])
- hidden(Tensor[1, batch_size, hid_dim])
- cell(Tensor[1, batch_size, hid_dim])
'''
embedded = self.dropout(self.embedding(src)) # (seq_length, batch_size) -> (seq_length, batch_size, emb_dim)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
class Decoder(nn.Module):
def __init__(self,
seq_length,
emb_dim,
hid_dim,
trg_n_tokens,
drop_p = 0):
'''
inputs:
- seq_length(int): seq_length of target
- emb_dim(int): emb_dim of embedding matrix
- hid_dim(int): hidden dim of rnn
- trg_n_tokens(int): total number of tokens in target
- drop_p(float): drop_p after embeddding
'''
super(Decoder, self).__init__()
self.seq_length = seq_length
self.trg_n_tokens = trg_n_tokens
self.embedding = nn.Embedding(trg_n_tokens, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim)
self.fc = nn.Linear(hid_dim, trg_n_tokens)
self.dropout = nn.Dropout(drop_p)
def forward(self, trg, hidden, cell):
'''
inputs:
- trg(Tensor[batch_size])
- hidden(Tensor[1, batch_size, hid_dim])
- cell(Tensor[1, batch_size, hid_dim])
returns:
- output(Tensor[batch_size, n_tokens]):
- hidden(Tensor[1, batch_size, hid_dim]):
- cell(Tensor[1, batch_size, hid_dim])
'''
trg = trg.unsqueeze(0) # (1, batch_size)
embedded = self.dropout(self.embedding(trg)) # (1, batch_size, emb_dim)
output, (hidden, cell) = self.rnn(embedded, (hidden, cell)) # output: (1, batch_size, hid_dim)
output = output.squeeze(0)
output = self.fc(output) # output: (batch_size, n_tokens)
return output, hidden, cell
Decoder RNN in Seq2Seq¶
Decoder의 경우 context vector와 SOS Token을 시작으로 output을 예측해야 합니다.
각 결과값과 hidden state를 Decoder에 feed함으로써 output sentence를 생성해야 하므로 Encoder RNN과 다르게 반복문을 통해서 제어를 해야합니다.
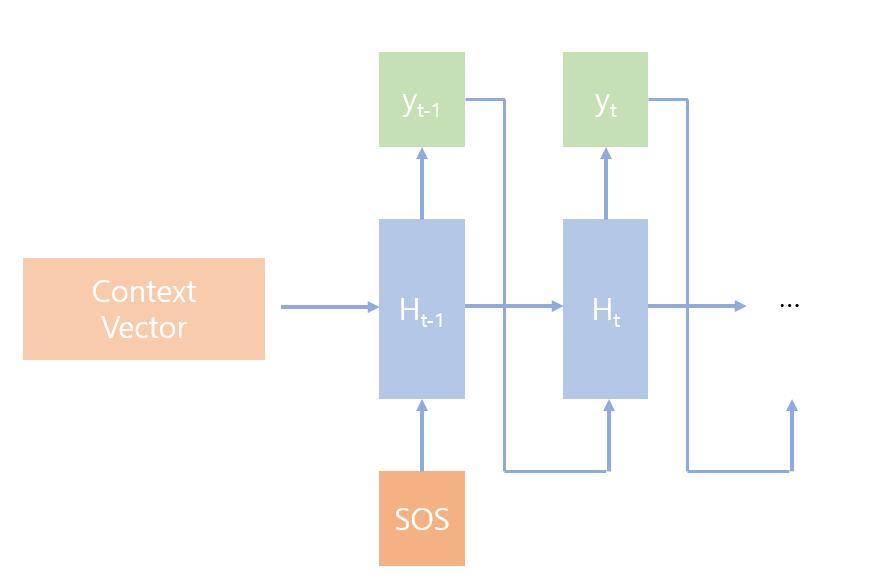
다만 output sentence의 정답 token(ground truth token)을 랜덤으로 feed하여 model을 올바르게, 빠르게 학습할 수 있습니다.
이 확률을 teacher forcing ratio로 설정합니다.
주의
모델의 성능을 평가(evaluation)할 때 teacher forcing은 사용하면 안됩니다!!
class Seq2Seq(nn.Module):
def __init__(self,
encoder,
decoder,
device):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio = 0.75):
'''
inputs:
- src(Tensor[src_seq_length, batch_size])
- trg(Tensor[trg_seq_length, batch_size])
- teacher_forcing_ratio(float): input of decoder will be ground truths token or prediction following by ratio
'''
outputs, hidden, cell = self.encoder(src)
seq_len = trg.size(0)
batch_size = trg.size(1)
trg_n_tokens = self.decoder.trg_n_tokens
logits = torch.zeros((seq_len, batch_size, trg_n_tokens)).to(device)
input = trg[0, :] # input(Tensor[batch_size])
for i in range(1, seq_len):
output, hidden, cell = self.decoder(input, hidden, cell)
logits[i] = output
top1 = output.argmax(1)
if self.training: # We should not use teacher forcing when eval
input = trg[i] if random.random() < teacher_forcing_ratio else top1
else:
input = top1
return logits
BATCH_SIZE = 32
n_pairs = len(pairs)
src = torch.zeros((MAX_LENGTH, n_pairs), dtype = torch.long)
trg = torch.zeros((MAX_LENGTH, n_pairs), dtype = torch.long)
for i in range(n_pairs):
src[:, i:i+1], trg[:, i:i+1] = tensorsFromPair(pairs[i])
batch = (torch.split(src, BATCH_SIZE, dim = 1), torch.split(trg, BATCH_SIZE, dim = 1))
emb_dim = 256
hid_dim = 512
src_n_tokens = input_lang.n_words
trg_n_tokens = output_lang.n_words
encoder = Encoder(seq_length = MAX_LENGTH,
emb_dim = emb_dim,
hid_dim = hid_dim,
n_tokens = src_n_tokens,
num_layers = 1,
drop_p = 0.5)
decoder = Decoder(MAX_LENGTH,
emb_dim,
hid_dim,
trg_n_tokens,
drop_p = 0)
model = Seq2Seq(encoder, decoder, device)
with torch.no_grad():
model.eval()
logits = model(batch[0][0], batch[1][0]) # test
How to train & evaluate model in PyTorch¶
1) model에 적합한 dataset(전체 데이터), dataloader(batch sized data set, iterable) 정의
2) trian(model, loss_fn, optimizer, ...)
3) eval(model, loss_fn, optimizer, ...)
4) Inference(test dataset)
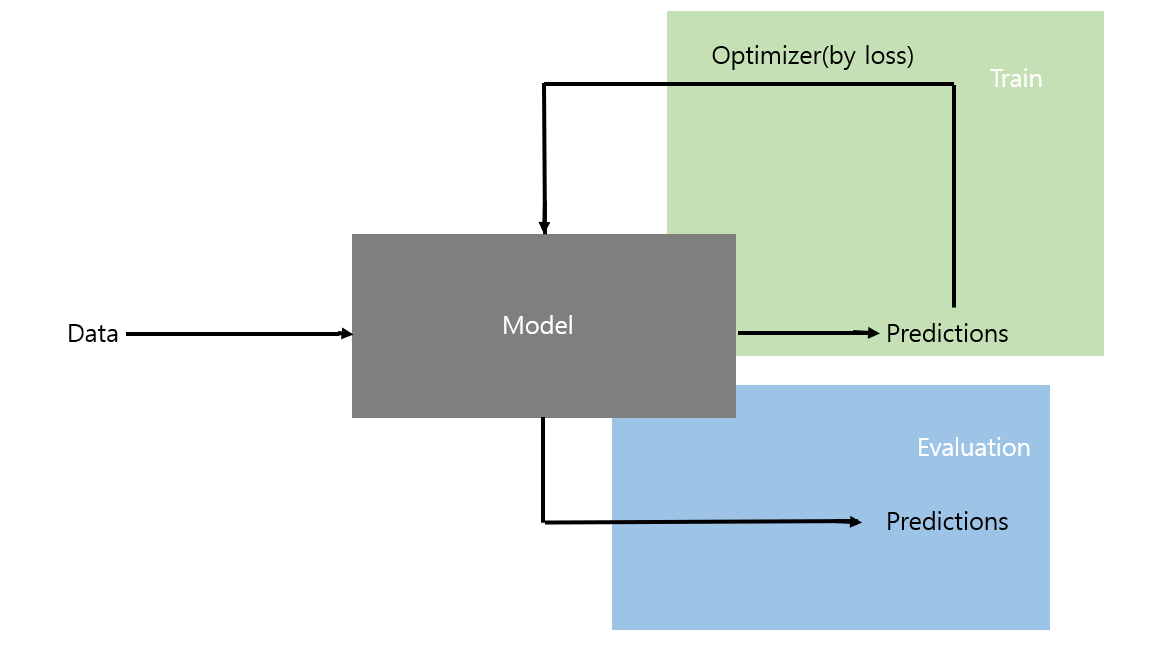
1, 4) 생략¶
2, 3) train, eval¶
# pseudo code
def train_one_epoch():
'''
1) model을 train mode로 변환
(batchnorm, dropout과 같이 train, eval일 때 각기 다른 방식으로 작용하는 layer를 위해 pytorch에서 제공하는 attribute)
2) dataloader 반복적으로 model에 feed
3) outputs = model(dataloader)
4) loss 계산 (loss_fn(outputs, labels))
5) optimizer 초기화
6) back propagation(loss.backward())
7) optimizer step
8) print(loss, accuracy, ...), model save, etc...
'''
def evaluate():
'''
1) model을 eval mode로 변환
2) with torch.no_grad():
similar train_one_eopch (except for optimizer)
3) print, model save, etc...
'''
위의 train, eval 함수를 num_epochs 만큼 반복해야하므로 반복문으로 이를 감싸주고 PyTorch 문법에 맞게 변환해주면 됩니다.
# pseudo code
def run(num_epochs, ...):
for epoch in range(num_epochs):
train_one_epoch()
scheulder.step() if scheduler
evaluate()
def train_one_epoch(model, train_dl, optimizer, loss_fn, ...):
model.train()
for (inputs, labels) in train_dl:
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''
log(loss, accuracy, ...)
model save or not
etc...
'''
def evaluate(model, eval_dl, loss_fn, ...):
model.eval()
with torch.no_grad():
for (inputs, labels) in eval_dl:
outputs = model(inputs)
_, preds = torch.max(outputs, -1)
loss = loss_fn(output, labels)
'''
log
model save or not
etc...
'''
Let's train model¶
def train(model, batch, optimizer, loss_fn, device, clip = 1 ):
'''
inputs:
- model
- batch(Tuple(src Tensor, trg Tensor)): Tensor.size() = (seq_length, batch_size)
- optimizer
- loss_fn
- device: GPU or CPU
- clip(float): protect gardient exploding by limiting max norm of gradient
outputs:
- running_loss(float): total loss in train one epoch
'''
model.train()
model = model.to(device)
loss_fn = loss_fn.to(device)
running_loss = 0.0
for i, (src, trg) in enumerate(zip(batch[0], batch[1])):
src, trg = src.to(device), trg.to(device)
logits = model(src, trg) # logits: [seq_length, batch_size, n_tokens]
n_tokens = logits.size(-1)
logits = logits[1:].reshape(-1, n_tokens) # remove <sos> token and flatten (seq_length * batch_size - 1, n_tokens)
trg = trg[1:].reshape(-1) # (seq_length * batch_size - 1)
optimizer.zero_grad()
loss = loss_fn(logits, trg)
running_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
return running_loss
def evaluation(model, batch, loss_fn, device):
'''
inputs:
- model
- batch(Tuple): (src Tensor, trg Tensor) (*Tensor.size() = (seq_length, batch_size))
- loss_fn
- device: GPU or CPU
outputs:
- running_loss(float): total loss in evaluation one epoch
'''
model.eval()
model = model.to(device)
loss_fn = loss_fn.to(device)
running_loss = 0.0
with torch.no_grad():
for i, (src, trg) in enumerate(zip(batch[0], batch[1])):
src, trg = src.to(device), trg.to(device)
logits = model(src, trg) # logits: [seq_length, batch_size, n_tokens]
n_tokens = logits.size(-1)
logits = logits[1:].reshape(-1, n_tokens) # remove <sos> token and flatten (seq_length * batch_size - 1, n_tokens)
trg = trg[1:].reshape(-1) # (seq_length * batch_size - 1)
loss = loss_fn(logits, trg)
running_loss += loss.item()
return running_loss
def run(model, train_batch, val_batch, loss_fn, optimizer, num_epochs, device, print_every = 100, clip = 1):
'''
wrapper of train and evaluation
'''
min_loss = float('inf')
best_model = None
for epoch in range(num_epochs):
total_train_loss = train(model, train_batch, optimizer, loss_fn, device, clip)
total_val_loss = evaluation(model, val_batch, loss_fn, device)
if (epoch+1) % print_every == 0 or epoch == 0:
print(f'Epoch| {epoch+1}/{num_epochs}')
print(f'train loss: {total_train_loss/len(train_batch[0])}')
print(f'val loss: {total_val_loss/len(val_batch[0])}')
if min_loss > total_val_loss:
min_loss = total_val_loss
best_model = copy.deepcopy(model)
return best_model
split dataset¶
model을 train할 때 전체 dataset을 train set, validation set으로 나누어야 합니다.
train set에서는 실질적인 학습이 일어나고,
validation set에서는 model의 성능 평가가 비교적 객관적으로 이루어집니다.
만약 train set과 validation set에서 성능 차이가 크게나면 일반적으로 model이 overfitting 되었다고 생각하시면 됩니다.
# split data into train, val
train_ratio = 0.8
train_batch = (batch[0][:int(len(batch[0])*train_ratio)], batch[1][:int(len(batch[0])*train_ratio)])
val_batch = (batch[0][int(len(batch[0])*train_ratio):], batch[1][int(len(batch[0])*train_ratio):])
#loss_fn = nn.CrossEntropyLoss(ignore_index = 2) # ignore pad
loss_fn = nn.CrossEntropyLoss()
learning_rate =0.01
optimizer = optim.Adam(model.parameters(), lr = learning_rate)
best_model = run(model,
train_batch,
val_batch,
loss_fn,
optimizer,
num_epochs = 20,
device = device,
print_every = 1)
Epoch| 1/20
train loss: 2.0129036840639616
val loss: 2.505979177852472
Epoch| 2/20
train loss: 1.472409933491757
val loss: 2.6247515281041465
Epoch| 3/20
train loss: 1.2924475575748242
val loss: 2.564739376306534
Epoch| 4/20
train loss: 1.239480709088476
val loss: 2.505082373817762
Epoch| 5/20
train loss: 1.1373486481214825
val loss: 2.4709080681204796
Epoch| 6/20
train loss: 1.1013947875876176
val loss: 2.413986990849177
Epoch| 7/20
train loss: 1.0600982069969178
val loss: 2.4160922343532243
Epoch| 8/20
train loss: 1.0114873355940768
val loss: 2.4293998181819916
Epoch| 9/20
train loss: 0.9981789504226886
val loss: 2.464413784444332
Epoch| 10/20
train loss: 0.9680503820118151
val loss: 2.4953632528583207
Epoch| 11/20
train loss: 0.9409303674572392
val loss: 2.419907346367836
Epoch| 12/20
train loss: 0.9479612425753945
val loss: 2.4010447710752487
Epoch| 13/20
train loss: 0.9248014964555439
val loss: 2.5098216235637665
Epoch| 14/20
train loss: 0.9069469542879808
val loss: 2.384943505128225
Epoch| 15/20
train loss: 0.8886521326868158
val loss: 2.4789953331152597
Epoch| 16/20
train loss: 0.8597453164426904
val loss: 2.4796039909124374
Epoch| 17/20
train loss: 0.8495413730019017
val loss: 2.4304580440123877
Epoch| 18/20
train loss: 0.8567408367207175
val loss: 2.366885965069135
Epoch| 19/20
train loss: 0.8345932260939949
val loss: 2.309285076955954
Epoch| 20/20
train loss: 0.7917937056014412
val loss: 2.4754027103384337
결과값을 보시면 train loss와 val loss의 차이가 크게 나는 것을 아실 수 있습니다.
즉, overfitting이 되었는데 이에 대한 추측으로는
1) dataset 크기 부족
2) dataset이 적절하게 섞이지 않음
3) 모델 설계 오류
4) teacher forcing에 따른 성능 차이
2)의 경우 txt 파일을 보시면 비슷한 문장이 계속 나열되는 것을 아실 수 있습니다.
이를 해결하기 위해 먼저 pair를 random shuffle하였기 때문에 어느정도 방지했다고 생각합니다.
3)의 경우를 해결하기 위해 dropout, LSTM, optimizer clip 등을 사용하여 overfitting을 방지하였습니다.
다른 방안으로는 weight decay, RNN layer 조절 등이 있습니다.
ref: https://discuss.pytorch.org/t/simple-encoder-decoder-model-is-overfitting/74632
dataset의 크기가 부족하다고는 생각하지 않으므로 teacher focing에 따른 성능 차이로 생각합니다.
혹시 문제점을 발견하셔서 알려주시면 감사하겠습니다.
모델 결과값(validation dataset) 확인¶
test_batch = 10
pick = random.randint(0, len(val_batch[0]) - 1)
with torch.no_grad():
best_model.eval()
best_model = best_model.to(device)
src, trg = val_batch[0][pick], val_batch[1][pick]
src, trg = src.to(device), trg.to(device)
logits = model(src, trg)
preds = logits.argmax(-1)
# [seq_length, batch_size] -> [batch_size, seq_length] (for simply treating sentences)
preds = preds.T
src = src.T
trg = trg.T
for i in range(test_batch):
input_sentence = [input_lang.index2word[src.item()] for src in src[i]]
answer = [output_lang.index2word[trg.item()] for trg in trg[i]]
pred = [output_lang.index2word[pred.item()] for pred in preds[i]]
print('source sentence: ', ' '.join(input_sentence[1:]))
print('answer translation: ', ' '.join(answer[1:]))
print('pred translation : ', ' '.join(pred[1:]))
print(' ')
source sentence: il travaille de nuit ce soir . <EOS> <PAD>
answer translation: he is on night duty tonight . <EOS> <PAD>
pred translation : he is afraid of his own . <EOS> <PAD>
source sentence: je ne vais pas travailler . <EOS> <PAD> <PAD>
answer translation: i m not going to work . <EOS> <PAD>
pred translation : i m not going . <EOS> <PAD> <PAD> <PAD>
source sentence: je me specialise en sociologie . <EOS> <PAD> <PAD>
answer translation: i m majoring in sociology . <EOS> <PAD> <PAD>
pred translation : i m going to get married . <EOS> <PAD>
source sentence: tu es l elue . <EOS> <PAD> <PAD> <PAD>
answer translation: you are the one . <EOS> <PAD> <PAD> <PAD>
pred translation : you re the teacher . <EOS> <PAD> <PAD> <PAD>
source sentence: il est deprime . <EOS> <PAD> <PAD> <PAD> <PAD>
answer translation: he s depressed . <EOS> <PAD> <PAD> <PAD> <PAD>
pred translation : he is powerful . <EOS> <PAD> <PAD> <PAD> <PAD>
source sentence: je ne suis pas tres patiente . <EOS> <PAD>
answer translation: i m not very patient . <EOS> <PAD> <PAD>
pred translation : i m not a saint . <EOS> <PAD> <PAD>
source sentence: nous en avons fini ici . <EOS> <PAD> <PAD>
answer translation: we re finished here . <EOS> <PAD> <PAD> <PAD>
pred translation : we re all retired . <EOS> <PAD> <PAD> <PAD>
source sentence: vous n etes pas invitee . <EOS> <PAD> <PAD>
answer translation: you aren t invited . <EOS> <PAD> <PAD> <PAD>
pred translation : you re not dead yet . <EOS> <PAD> <PAD>
source sentence: tu es fort contrariee . <EOS> <PAD> <PAD> <PAD>
answer translation: you re very upset . <EOS> <PAD> <PAD> <PAD>
pred translation : you re very upset . <EOS> <PAD> <PAD> <PAD>
source sentence: elles sont de retour . <EOS> <PAD> <PAD> <PAD>
answer translation: they re back . <EOS> <PAD> <PAD> <PAD> <PAD>
pred translation : they re out of town . <EOS> <PAD> <PAD>
'딥러닝 > 자연어 처리(NLP)' 카테고리의 다른 글
| PyTorch로 번역기 구현하기 vol 2 (0) | 2022.12.07 |
|---|