2023. 1. 15. 00:27ㆍ딥러닝/PyTorch
목차¶
- Overview
- Data load from folder
- torch.utils.data.Dataset
- Data Split(train dataset & validation dataset)
- torch.utils.data.DataLoader
- Make Deep Learning Model
- Train & eval
- Predict(or Inference)
- submit(ex. make csv file)
- Remind
Overview¶
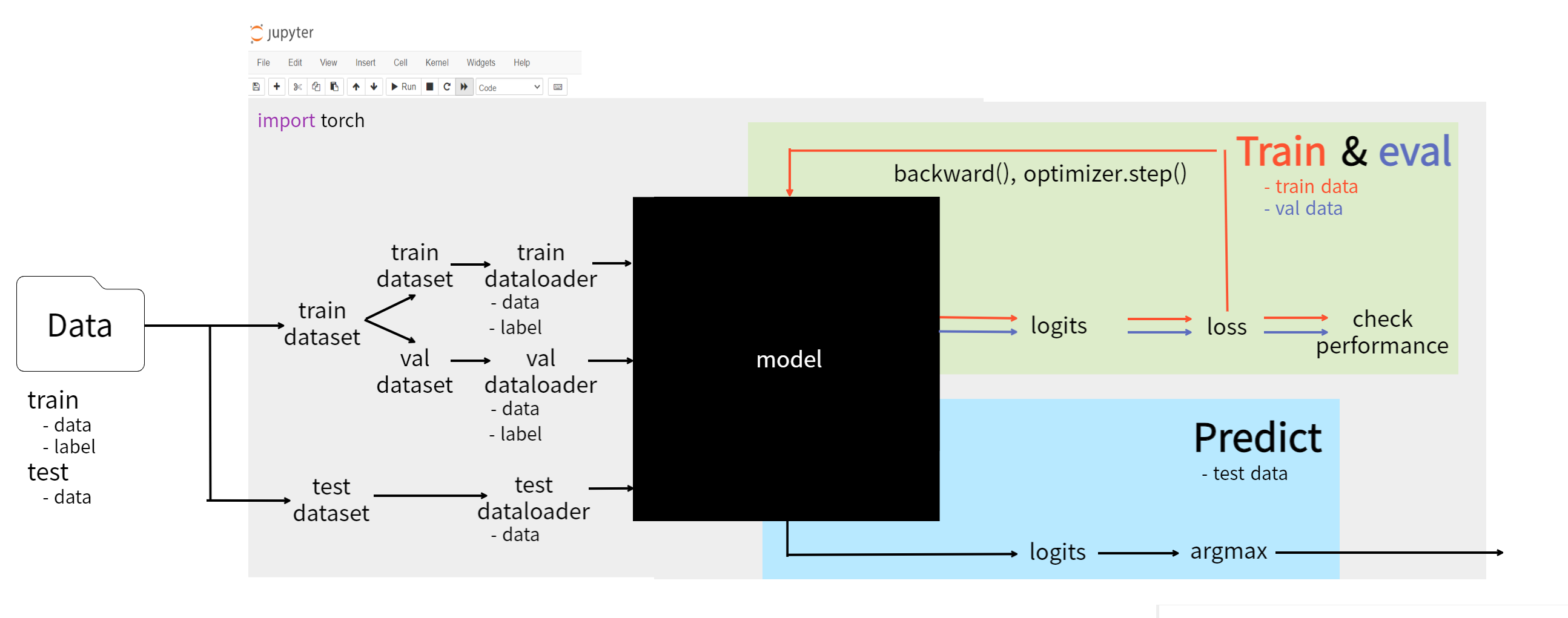
PyTorch를 통한 Deep Learning 알고리즘은 큰 틀에서 정형적으로 짜여져있습니다.
지금부터 이 틀에 대해 설명드리고자 합니다.
caution
지금부터 설명드릴 내용이 각 모델, task에 최적의 방법은 아닙니다.
때로는 task에 따라 동작하지 않을 수 있습니다.
하지만 처음 PyTorch를 접하는 개발자가 각 task에 따른 다양한 방법론을 살펴봄에 따라 발생하는 어려움을 방지하기 위해 해당 글을 포스팅합니다.
틀린 내용 및 이론이 있다면 너른 마음으로 이해해주시고 댓글 달아주시면 감사하겠습니다.
Data load from folder
- folder안에 있는 train & test data를 불러오고
Dataset & DataLoader
- torch.utils.data.Dataset 모듈을 이용하여 전체 Dataset을 model에 어떻게 feed할 것인지 설정한 후
- train dataset의 경우 다시 train dataset과 validation dataset으로 나눕니다.
- 이후 batch 학습을 위해 dataset을 dataloader를 이용하여 iterable object로 변환한 후
train & eval
- Deep Learning model에 반복적으로 data를 feed합니다.
- model의 결과값으로 산출된 logits과 Dataset label, loss function을 통해 loss를 산출하고
- 해당 loss를 통해 model의 성능을 대략적으로 평가하고 train data의 경우 loss와 optimizer를 통해 모델을 훈련시킵니다.
predict(or Inference)
- 최종적으로 가장 좋은 성능을 보이는 모델을 통해 test data를 feed 하여
- 가장 높은 확률을 보이는 결과값을 예측값으로 선정합니다.
- 각 project에 적합하게 해당 결과값을 변환 해줍니다.(csv, text file, DB, etc.)
Data load from folder & torch.utils.data.Dataset¶

Data load from folder
folder 안에 있는 data를 불러오기 위해선
- 해당 folder의 경로
- 경로를 통해 folder 안의 data를 불러올 수 있는 알고리즘
이 필요합니다.
- data를 불러오는 알고리즘은 주로 python 내장함수나 외부 라이브러리를 이용합니다.
예시를 위해 다음의 폴더구조를 가정해보겠습니다.
root
├── src.py
└── data
├── train
│ ├── train_data
│ └── label
└── test
└── test_data
data_root = os.path.join(root, 'data')
train_path = os.path.join(data_root, 'train')
test_path = os.path.join(data_root, 'test')
# text file
with open(os.path.join(train_path, train_data)) as f:
lines = f.read()
# image file
'''
image file의 경우
1. PIL library
2. opencv library
3. matplotlib library
4. glob library
등 다양한 방법이 존재한다.
'''
import os
from PIL import Image
def get_image(path, idx):
'''
image의 경우 폴더 안에 여러 이름을 가지는 image파일이 존재하는 경우가 일반적입니다. (ex. image_01.png, image_02.png, ...)
따라서 폴더 안의 각 image파일들의 이름을 모두 알아야할 필요가 있는데, os.listdir() 함수를 이용하면 이를 쉽게 해결할 수 있습니다.
Parameters:
- path(str): train data path or test data path
- idx(int)
Returns:
- image
'''
img_names = os.listdir(path)
img_path = os.path.join(path, img_names[idx])
return Image.open(img_path)
torch.utils.data.Dataset
Model에 data를 feed하기 위해선
- Preprocessing (ex. image 사이즈 통일, torch.tensor로 변환 등)
- 전체 data set을 batch size를 가지는 data 조각들로 분할
- 반복문을 통해 data 조각을 model에 지속적으로 feed
해야합니다.
PyTorch는 일련의 과정을 Dataset 모듈과 DataLoader 모듈로 해결하는 솔루션을 제공합니다.
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self):
pass
def __len__(self):
pass
def __getitem__(self):
pass
nn.Module과 비슷하게 Dataset 또한 기본적으로 init, len, getitem 함수만 정의하면 작동하는 방식으로 이루어져 있습니다.
PyTorch는 Dataset 모듈을 통해 사용자가 마치 전체 데이터 셋을 list와 같은 방식으로 편하게 다룰 수 있게 해줍니다.
특징
Indexing
- list[idx] = some value
len(list) = 리스트 안에 존재하는 전체 데이터의 갯수
init 함수의 경우 주로
data path를 인수로 받아 file에 접근하기 위한 초기화 작업
preprocessing을 위한 초기화 작업
을 이용하고,
len 함수의 경우 전체 data의 크기를 return해야 합니다.
dataset_size = len(CustomDataset)
getitem은 index를 통해 전체 dataset에서 하나의 데이터에 접근할 수 있는 함수입니다.
some_data = CustomDataset[index]
train & val data의 경우 주로 model에 직접적으로 feed할 data와 정답(label)을 return 합니다.
다음은 image classification task를 수행할 경우의 예시 코드입니다.
from torch.utils.data import Dataset
import torchvision.transforms as T
import pandas as pd
data_root = os.path.join(root, 'data')
class ImgDataset(Dataset):
def __init__(self, data_root, mode, transform = None, target_transform = None):
'''
Suppose label is csv file
label.csv
| img_name | | label |
------------------------
|'img_1.png'| | cat |
|'img_2.png'| | dog |
We have to map the label to int number (because model output will be tensor)
ex. 'cat' -> 0, 'dog' -> 1
Parameters:
- data_root(str)
- mode(str): train or test
- transform(torchvision.transforms): preprocess the data
- target_transform(torchvision.transforms): preprocess the label
'''
if mode == 'train':
self.img_path = os.path.join(data_root, 'train', 'train_data')
self.label_path = os.path.join(data_root, 'train', 'label.csv')
self.csv = pd.read_csv(self.label_path)
self.labels = self.csv['label'].unique().tolist()
self.n_classes = len(self.labels)
self.idx_to_label = {i: label for i, label in zip(range(self.n_classes), self.labels)}
self.label_to_idx = {label: i for i, label in zip(range(self.n_classes), self.labels)}
elif mode == 'test':
self.img_path = os.path.join(data_root, 'test', 'test_data')
self.mode = mode
self.img_names = os.listdir(self.img_path)
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_names)
def __getitem__(self, idx):
'''
Each data will be returend following by index
Parameters:
- idx(int)
Returns:
when mode == 'train'
- img(Tensor[num_channel, width, height])
- label(Tensor[1]): label(str) will be mapped to int(0~num_classes)
ex) 'cat' -> 0, 'dog' -> 1, ...
when mode == 'test'
- img(Tensor[num_channels, width, height])
- img_name(str): image file name
'''
if self.mode == 'train':
img_name = self.csv['img_name'][idx]
img_path = os.path.join(self.img_path, img_name)
img = Image.open(img_path)
label = self.csv['label'][idx]
label = self.label_to_idx[label]
if self.transform is not None: # transform ex. T.ToTensor()
img = self.transform(img)
if self.target_transform is not None:
label = self.target_transform(label)
return img, label
elif self.mode == 'test':
img_name = self.img_names[idx]
img_path = os.path.join(self.img_path, img_name)
img = Image.open(img_path)
if self.transform is not None:
img = self.transform(img)
return img, img_name
Data Split(train dataset & validation dataset)¶
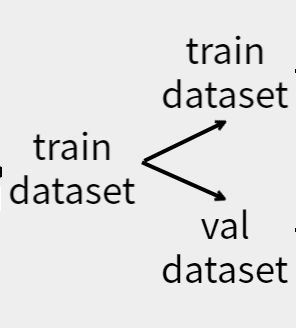
model을 학습하면서 올바르게 학습이 진행되고 있는지 확인할 필요가 있습니다.
하지만 직관적으로도 학습을 하고 있는 데이터를 통해 모델의 성능을 평가하는 데에는 어폐가 있습니다.
마치 문제집을 달달 외울 정도로 기억력이 좋은 학생에게 이미 정답을 알려준 문제를 주고 평가를 하는 형식이기 때문입니다.
즉, model은 처음 보는 문제(data)를 풀 능력이 있는지에 대해 평가를 해야합니다.
하지만 model은 또한 test data에 접근할 수 없는 문제점을 가지고 있습니다.
이러한 문제점을 해결하기 위해 전체 train dataset을 나누어 모델의 학습 능력을 평가하기 위한 가짜 test set(validation)과
모델을 학습하기 위한 train dataset으로 나누어야 합니다.
more information:
cs231n classification (topic: validatoin sets for Hyperparameter tuning)
from torch.utils.data import random_split
img_dataset = ImgDataset(some_initial_parameters)
train_set, val_set = random_split(img_dataset, [0.8, 0.2])
만약 sklearn.model_selection.train_test_split() 함수를 이용하여 data를 나누고 싶으시면,
다음 사이트를 참고해주세요.
pytorch discuss
torch.utils.data.DataLoader¶
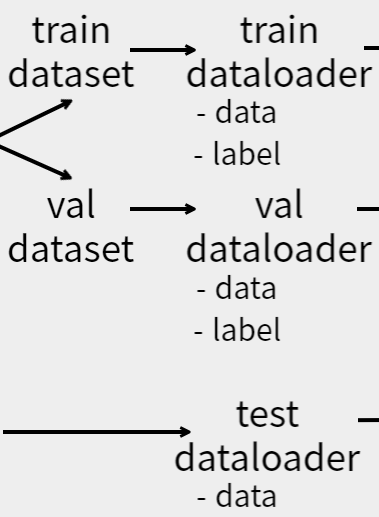
model을 훈련하기 위한 data 크기는 일반적으로 많을수록 좋습니다.
따라서 훈련용 data 크기는 일반적으로 매우 많은 용량을 차지합니다.
이를 한번에 model에 feed할 경우 컴퓨터 자원이 매우 많이 소비되며 시간 또한 오래 걸립니다.
또한 성능 면에서도 전체 데이터를 통해 학습하는 것이나 일부 데이터를 통해 학습하는 것이나 크게 차이가 나지 않습니다.[1](#footnote_1)
이에 따라 적정 크기(64 or 128, cf. 2n)로 데이터를 조각내서 model에 지속적으로 feed 하는 방법을 이용합니다.[2](#footnote_2)
PyTorch의 DataLoader 모듈을 이용하면 쉽게 data를 나누어[3](#footnote_3) 반복가능한 객체(Iterable)로 만들 수 있으며,
관련된 속성을 쉽게 부여할 수 있습니다.
from torch.utils.data import DataLoader
train_dl = DataLoader(train_set, batch_size = 64, shuffle = True)
val_dl = DataLoader(val_set, batch_size = 64, shuffle = True)
for more infomration:
- 1: why SGD works?
- 2: What is the advantage of keeping batch size a power of 2?
- 3: 한 예시로 전체 데이터가 100개이고 batch_size가 64개일 때 마지막 남은 데이터 조각들(100 % 64)에 대한 처리를 자동으로 해줍니다.
- PyTorch DataLoader (Official docs)
Make Deep Learning Model¶

model을 설계하는 방법은 따로 포스팅을 했기 때문에 transfer learning에 대해서만 간략히 설명 드리겠습니다.
현재 모델링을 연구하는 사람이나 새로운 task를 풀기 위한 경우가 아니고서야 모델을 직접 설계하는 사람은 드물 것 같습니다.
이미 성능이 검증된 model이 각 task에 있고 검증된 dataset을 통한 학습된 model을 많은 기관 또는 개인이 배포하고 있습니다.
많은 사람들은 이 학습된 model을 transfer learning을 통해 자신의 data에 최적화합니다.
transfer learning[1](#footnote_1)
방대하고 검증된 dataset(ex. ImageNet)을 통해 학습된 model은 data 특성을 잘 추출하는 특성을 가지고 있습니다.
이러한 특징은 학습에 존재하지 않는 data에 대해서도 유효하게 작동합니다.
이를 통해 새로운 데이터에 최적화된 결과를 산출하도록 미세하게 parameter를 조정하면 많은 시간과 자원을 들이지 않고 우수한 결과값을 얻을 수 있습니다.
cf) 일반적으로 모델의 초기 layer에서는 데이터(ex. 이미지)의 전반적인 특성을 추출하고 layer가 깊어질수록 데이터의 세부 특성을 더욱 많이 반영합니다.
import torch.nn as nn
from torchvision.models.resnet import resnet18 as _resnet18
if model_name == 'resnet':
pretrained_model = _resnet18(pretrained = True)
# image의 일반적 특성을 추출하는 backbone은 학습이 되지 않게 설정합니다.
# (데이터 변경으로 잘못 학습될 가능성 있음 + 최적화 시간이 더욱 많이 걸릴 수 있음)
for param in pretrained_model.parameters():
param.requires_grad = False
# task에 적합한 label의 갯수로 마지막 linear layer를 변환해줍니다.
# nn.Linear의 default값으로 parameter.requires_grad = True이므로 classification linear layer만 학습이 진행됩니다.
in_features = pretrained_model.fc.in_features
pretrained_model.fc = nn.Linear(in_features, n_labels)
for more inforamtion:
Train & eval¶
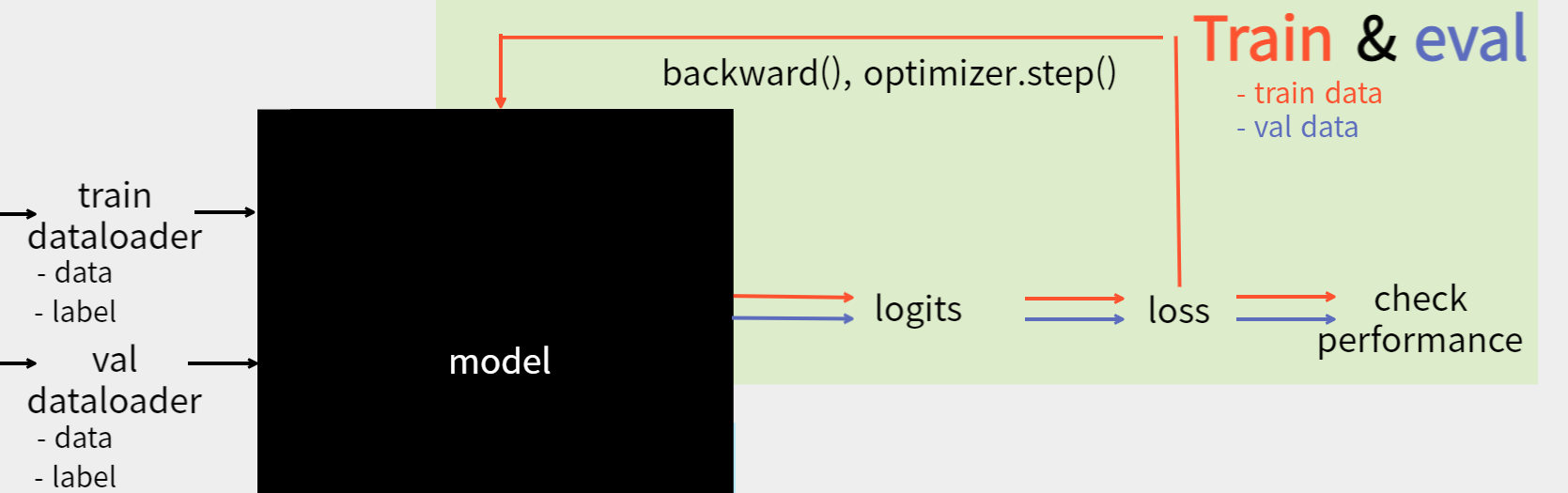
이제,
- train data loader를 반복적으로 model에 feed 합니다.
- 모델 결과값(logits)과 정답(label), loss function을 통해 loss를 계산합니다.
- backward와 optimizer를 통해 모델을 최적화합니다.
- 전체 train dataset에 대한 학습이 끝나면 validation data를 통해 모델의 성능을 평가합니다.
- 평가 결과 가장 좋은 성능을 보이는 model은 따로 저장합니다.
- 위의 과정을 종료조건까지 반복합니다.
주의점 check list
model을 각 모드에 맞게 변경하였는지? (model.train(), model.eval())
batch normalization / drop out과 같이 train, eval일 때 다르게 작동하는 layer를 위한 pytorch 모듈backward 전 gradient를 0으로 초기화했는지?
PyTorch에서 model parameter의 gradient는 누적됩니다.
이에 따라 매 반복마다 0으로 초기화를 먼저 진행해줘야합니다.
more information: why you should set zero_grad(), micro grad by andrej karpathy (from 01:22:28)optimizer를 선언하기 전에 model을 먼저 device에 옮겼는지?
pytorch issues 7321eval or predict일 경우 with torch.no_grad() (cf. gradient가 쌓이지 않도록 적용)
train과 eval은 전체적으로 매우 비슷한 구조를 가집니다.
가장 큰 차이점은 backward와 optimizer를 통해 모델이 학습을 하느냐 아니냐입니다.
cf) epoch은 전체 dataset을 한 번 순회했을 때를 말합니다.
import torch.nn as nn
import torch.optim as optim
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device) # optimizer를 선언하기 전에 model parameter를 먼저 해당 device에 옮겨야합니다!
optimizer = optim.Adam(model.parameters(), lr = 1e-4, weight_decay = 1e-2)
loss_fn = nn.CrossEntropyLoss()
def train_epoch(model, train_dl, loss_fn, optimizer, device):
n_corrects = 0
n_data = len(train_dl.dataset)
model.train()
for i, (data, labels) in enumerate(train_dl):
data, labels = data.to(device), labels.to(device)
logits = model(data)
loss = loss_fn(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
preds = torch.argmax(logits, dim = -1)
n_corrects += toch.sum(preds == labels).item()
accuracy = n_corrects / n_data
def eval_epoch(model, val_dl, optimizer, device):
n_corrects = 0
n_data = len(val_dl.dataset)
model.eval()
for i, (data, labels) in enumerate(val_dl):
with torch.no_grad():
data, labels = data.to(device), labels.to(device)
logits = model(data)
loss = loss_fn(logits, labels)
val_loss_hist.append(loss)
preds = torch.argmax(logits, dim = -1)
n_corrects += toch.sum(preds == labels).item()
accuracy = n_corrects / n_data
return accuracy
한 번의 Epoch으로 학습을 하지 않고 여러 번의 Epoch을 통해 모델을 train & eval하기 때문에,
위의 함수를 반복문으로 감싸주어 번갈아가며 실행해야 합니다.
train_epoch() -> eval_epoch() -> train_epoch() -> eval_epoch() -> ...
EPOCHS = 20
best_model, best_acc = None, float('-inf')
for epoch in range(EPOCHS):
train_epoch(model, train_dl, loss_fn, optimizer, device)
val_acc = eval_epoch(model, val_dl, optimizer, device)
if best_acc < val_acc:
best_model = model
best_acc = val_acc
cf) train과 eval 함수는 많은 parameter를 공유하는 것을 알 수 있습니다.
이를 class로 작성하여 코드를 간결하게 만들고 유지보수하기 쉽게 만들 수 있습니다.
Predict(or Inference)¶
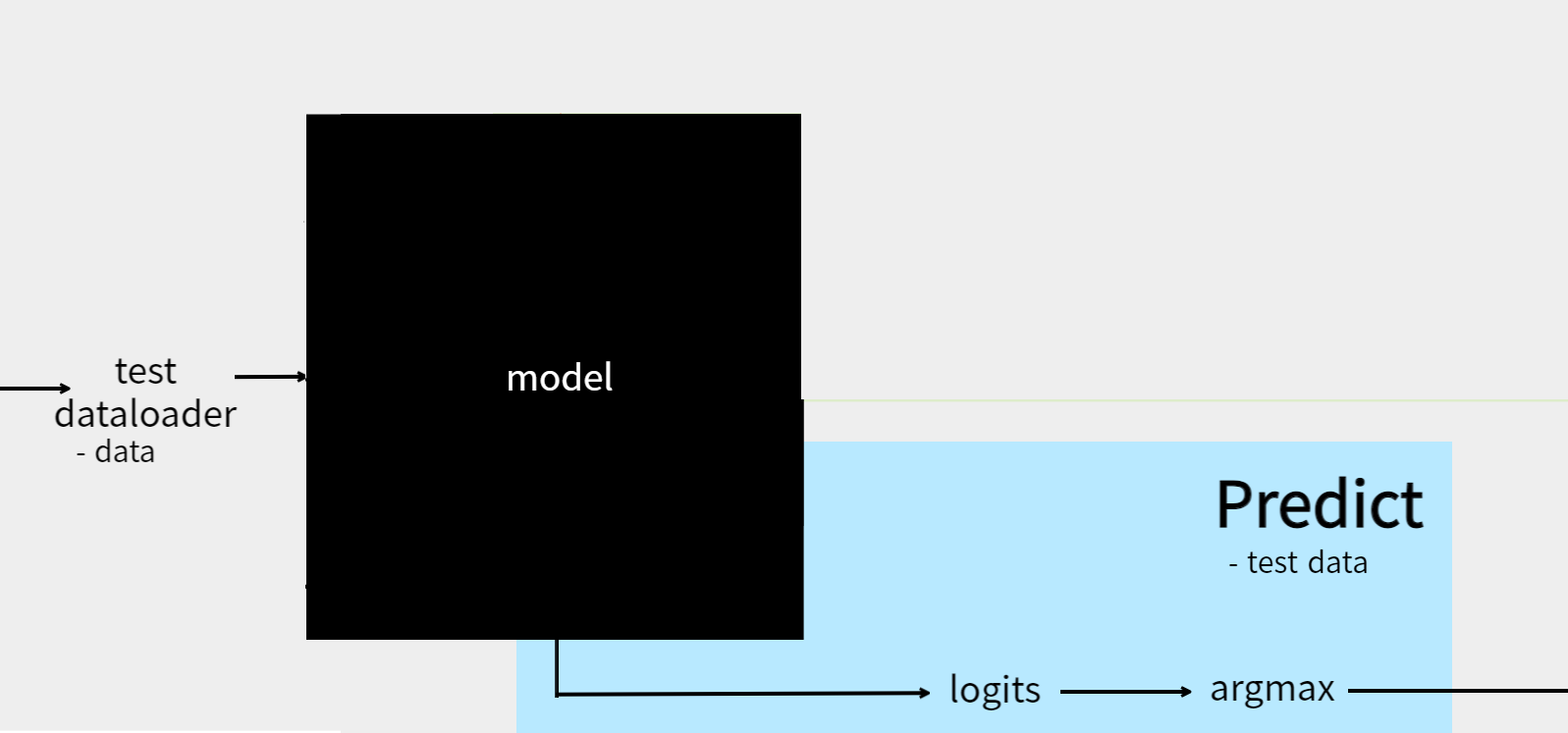
위의 ImgDataset에서 mode == 'test'일 경우 image와 image file의 이름을 반환하도록 설정하였습니다.
이는 해당 이미지 파일 이름에 따라 label을 분류하기 위한 작업으로 task마다 혹은 목적마다 다르게 구현하실 수 있습니다.
predict 또한 train & eval과 크게 다르지않습니다.
model의 결과값(logits)으로 부터 가장 확률이 높은 값을 예측값으로 선정하고 후처리를 하면 됩니다.
test_dl = DataLoader(test_set, batch_size = 64)
def predict(best_model, test_dl, img_dataset)
best_model.eval()
pred_list, file_list = list(), list()
with torch.no_grad():
for data, img_names in test_dl:
data = data.to(device)
logits = best_model(data)
preds = torch.argmax(logits, dim = -1)
pred_list.extend(preds.cpu().tolist())
file_list.extend(img_names)
pred_list = list(map(lambda x: img_dataset.idx_to_label[x], pred_list)) # 0 -> cat, 1 -> dog, ...
return pred_list, file_list
submit(ex. make csv file)¶
kaggle이나 dacon같은 딥러닝 경진대회인 경우 csv file로 변환하여 제출하는 경우가 많기 때문에 이를 위한 간단한 코드를 구현해보겠습니다.
pred_list, file_list = predict(best_model, test_dl)
SAVE_PATH = os.path.join(root, 'predict.csv')
def submit(pred_list, file_list, save_path)
pred_df = pd.DataFrame({'file_name': file_list, 'label': pred_list})
pred_df.to_csv(save_path, index = False)
Remind¶
import os
import pandas as pd
from PIL import Image
import copy
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import random_split
from torchvision.models.resnet import resnet18 as _resnet18
import torchvision.transforms as T
root = os.path.abspath(os.curdir) #ref: https://minorman.tistory.com/100
data_root = os.path.join(root, 'data')
# data load from folder & make Dataset
class ImgDataset(Dataset):
def __init__(self, data_root, mode, transform = None, target_transform = None):
'''
Suppose label is csv file
label.csv
| img_name | | label |
------------------------
|'img_1.png'| | cat |
|'img_2.png'| | dog |
Parameters:
- data_root(str)
- mode(str): train or test
- transform(torchvision.transforms): preprocess the data
- target_transform(torchvision.transforms): preprocess the label
'''
if mode == 'train':
self.img_path = os.path.join(data_root, 'train', 'train_data')
self.label_path = os.path.join(data_root, 'train', 'label.csv')
self.csv = pd.read_csv(self.label_path)
self.labels = self.csv['label'].unique().tolist()
self.n_classes = len(self.labels)
self.idx_to_label = {i: label for i, label in zip(range(self.n_classes), self.labels)}
self.label_to_idx = {label: i for i, label in zip(range(self.n_classes), self.labels)}
elif mode == 'test':
self.img_path = os.path.join(data_root, 'test', 'test_data')
self.mode = mode
self.img_names = os.listdir(self.img_path)
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_names)
def __getitem__(self, idx):
'''
Indexing
Each data will be returend following by index
Parameters:
- idx(int)
Returns:
when mode == 'train'
- img(Tensor[num_channel, width, height])
- label(Tensor[1]): label(str) will be mapped to int(0~num_classes)
ex) 'cat' -> 0, 'dog' -> 1, ...
when mode == 'test'
- img(Tensor[num_channels, width, height])
- img_name(str): image file name
'''
if self.mode == 'train':
img_name = self.csv['img_name'][idx]
img_path = os.path.join(self.img_path, img_name)
img = Image.open(img_path)
label = self.csv['label'][idx]
label = self.label_to_idx[label]
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
label = self.target_transform(label)
return img, label
elif self.mode == 'test':
img_name = self.img_names[idx]
img_path = os.path.join(self.img_path, img_name)
img = Image.open(img_path)
if self.transform is not None:
img = self.transform(img)
return img, img_name
transform = T.ToTensor()
train_dataset = ImgDataset(data_root, 'train', transform, target_transform = None)
# split train data into train and validation data
train_set, val_set = random_split(train_dataset, [0.8, 0.2])
# data loader
train_dl = DataLoader(train_set, batch_size = 64, shuffle = True)
val_dl = DataLoader(val_set, batch_size = 64, shuffle = True)
test_set = ImgDataset(data_root, 'test', transform, target_transform = None)
test_dl = DataLoader(test_set, batch_size = 64)
# transfer learning
def get_pretrained_resnet(n_labels):
pretrained_model = _resnet18(pretrained = True)
for param in pretrained_model.parameters():
param.requires_grad = False
in_features = pretrained_model.fc.in_features
pretrained_model.fc = nn.Linear(in_features, n_labels)
return pretrained_model
model = get_pretrained_resnet(train_dataset.n_classes)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr = 1e-4, weight_decay = 1e-2)
loss_fn = nn.CrossEntropyLoss()
# train & eval
class Trainer:
def __init__(self, model, train_dl, val_dl, loss_fn, optimizer, device):
self.model = model
self.train_dl, self.val_dl = train_dl, val_dl
self.loss_fn, self.optimizer = loss_fn, optimizer
self.device = device
# history
self.train_loss_hist, self.train_acc_hist = list(), list()
self.val_loss_hist, self.val_acc_hist = list(), list()
def train_epoch(self):
n_corrects = 0
n_data = len(self.train_dl.dataset)
self.model.train()
for i, (data, labels) in enumerate(self.train_dl):
data, labels = data.to(device), labels.to(device)
logits = self.model(data)
loss = self.loss_fn(logits, labels)
self.train_loss_hist.append(loss.item())
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
preds = torch.argmax(logits, dim = -1)
n_corrects += torch.sum(preds == labels).item()
accuracy = n_corrects / n_data
self.train_acc_hist.append(accuracy)
def eval_epoch(self):
n_corrects = 0
n_data = len(self.val_dl.dataset)
self.model.eval()
for i, (data, labels) in enumerate(self.val_dl):
with torch.no_grad():
data, labels = data.to(device), labels.to(device)
logits = model(data)
loss = loss_fn(logits, labels)
self.val_loss_hist.append(loss.item())
preds = torch.argmax(logits, dim = -1)
n_corrects += torch.sum(preds == labels).item()
accuracy = n_corrects / n_data
self.val_acc_hist.append(accuracy)
EPOCHS = 20
best_model, best_acc = None, float('-inf')
trainer = Trainer(model, train_dl, val_dl, loss_fn, optimizer, device)
for epoch in range(EPOCHS):
trainer.train_epoch()
trainer.eval_epoch()
if best_acc < trainer.val_acc_hist[-1]:
best_model = copy.deepcopy(model)
best_acc = trainer.val_acc_hist[-1]
# predict
test_dl = DataLoader(test_set, batch_size = 64)
def predict(best_model, test_dl, train_dataset):
best_model.eval()
pred_list, file_list = list(), list()
with torch.no_grad():
for data, img_names in test_dl:
data = data.to(device)
logits = best_model(data)
preds = torch.argmax(logits, dim = -1)
pred_list.extend(preds.cpu().tolist())
file_list.extend(img_names)
pred_list = list(map(lambda x: train_dataset.idx_to_label[x], pred_list))
return pred_list, file_list
pred_list, file_list = predict(best_model, test_dl, train_dataset)
SAVE_PATH = os.path.join(root, 'predict.csv')
# submmit
def submit(pred_list, file_list, save_path):
pred_df = pd.DataFrame({'file_name': file_list, 'label': pred_list})
pred_df.to_csv(save_path, index = False)
submit(pred_list, file_list, SAVE_PATH)