2022. 12. 7. 16:58ㆍ딥러닝/딥러닝 모델
# my github: https://github.com/withAnewWorld/models_from_scratch
# my blog
# https://self-deeplearning.blogspot.com/
# https://self-deeplearning.tistory.com/
import torch
import torch.nn as nn
import torch.nn.functional as F
Ref¶
- LeNet
paper: http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
Youtube(Aladdin Persson):
https://www.youtube.com/watch?v=fcOW-Zyb5Bo&list=PLhhyoLH6IjfxeoooqP9rhU3HJIAVAJ3Vz&index=16 - CNN
https://cs231n.github.io/convolutional-networks/ - Linear Classification
https://cs231n.github.io/linear-classify/
목차¶
- LeNet architecture
- torch.nn
- torch.nn.Module
- torch.nn.Sequential
- nn.Seuqntial in nn.Module
LeNet architecture¶
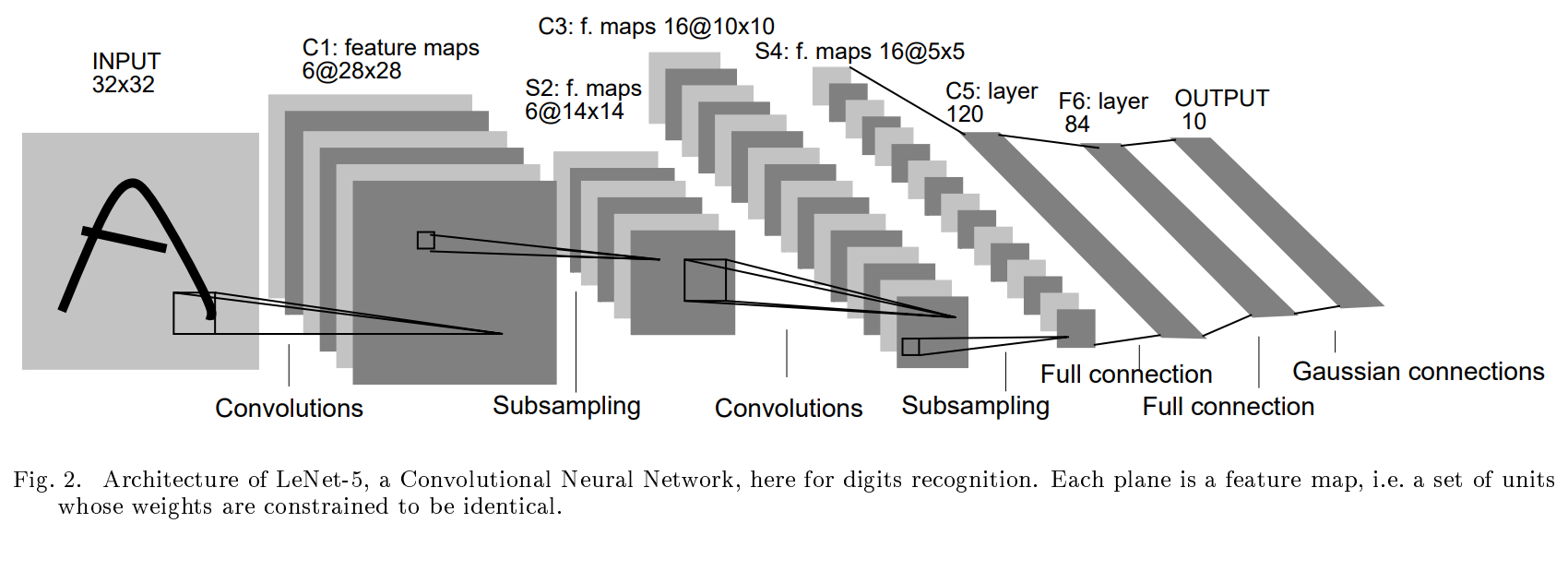
PyTorch model API
1) torch.nn
2) torch.nn.Module
3) torch.nn.Sequential
# pseudo code
def LeNet(image, num_classes):
'''
image classification task를 진행한다고 가정.
이미지 Tensor를 LeNet에 feed할 경우, 해당 이미지의 각 class의 logits(예측값)을 반환.
이 중 logit값이 가장 큰 값이 해당 network가 예측하는 class.
img의 크기(height, width)는 위의 예와 같이 32 x 32라고 가정.
inputs:
- image(Tensor[N, C, H, W])
- num_classes(int)
returns:
- logits(Tensor[N, num_classes])
'''
convolution network를 거친 후 image의 크기는 다음과 같이 변하게 됩니다.
W = 1 + (W - kernel_size + 2padding)/(stride) (no dilation conv)
H = 1 + (H - kernel_size + 2padding)/(stride) (no dilation conv)
논문 저자는 모든 conv net의 kernel_size를 5x5로 고정했습니다.
따라서, C1을 거친후 32x32의 image tensor가 28x28로 바뀌기 위해서 stride = 2
(모든 conv net padding = 0으로 고정)
이같은 방식으로 모든 conv net의 kernel_size, stride, padding을 설정할 수 있습니다.
sub-sampling의 경우 average pool을 사용했습니다.
```python
torch.nn¶
torch.nn에 존재하는 neural network 함수를 하나씩 이용해서 model을 설계하는 방법.
def LeNet(image, num_classes):
'''
inputs:
- image(Tensor[N, C, H, W]): (N: num_images, C: num_channels, H: image Height, W: image Width)
- num_classes(int)
returns:
- x(Tensor[N, num_classes])
'''
C1 = nn.Conv2d(in_channels = 1,
out_channels = 6,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0))
S2 = nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2))
C3 = nn.Conv2d(in_channels = 6,
out_channels = 16,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0))
S4 = nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2))
C5 = nn.Conv2d(in_channels = 16,
out_channels = 120,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0))
F6 = nn.Linear(in_features = 120, out_features = 84)
flatten = nn.Flatten()
classifier = nn.Linear(in_features = 84, out_features = num_classes)
x = C1(image)
print(x.size())
x = S2(x)
print(x.size())
x = C3(x)
print(x.size())
x = S4(x)
print(x.size())
x = C5(x)
print(x.size())
x = flatten(x)
print(x.size())
x = F6(x)
print(x.size())
x = classifier(x)
print(x.size())
return x
torch.manual_seed(42) # deterministic
image = torch.randn(64, 1, 32, 32)
num_classes = 10
output = LeNet(image, num_classes)
torch.Size([64, 6, 28, 28])
torch.Size([64, 6, 14, 14])
torch.Size([64, 16, 10, 10])
torch.Size([64, 16, 5, 5])
torch.Size([64, 120, 1, 1])
torch.Size([64, 120])
torch.Size([64, 84])
torch.Size([64, 10])
output[0]
tensor([-0.0533, -0.0760, 0.0290, -0.0205, 0.0147, -0.0804, -0.0519, -0.1315,
-0.1492, 0.0654], grad_fn=<SelectBackward0>)nn.Module¶
위와 같이 torch.nn에 존재하는 단순히 함수를 나열하여 개발을 할 경우 여러가지 문제가 발생합니다.
1) 모델의 크기가 커질수록 코드 가독성 현저하게 떨어짐
-> code refactoring 비용 증가
2) 현재 많은 model이 module화 되어 있기 때문에 특정 layers(block)을 교체하거나 수정하는 경우가 빈번합니다. 하지만 위의 방법대로는 매우 어렵습니다.
3) torch에서 제공하는 많은 API를 사용하기 어려워짐
see utils in nn.Module
https://pytorch.org/docs/stable/generated/torch.nn.Module.html
-> 해당 문제점은 모두 객체지향적으로 코드가 작성되어 있지 않기 때문에 발생하는 문제입니다.
-> 모델 그리고 모델을 이루는 모듈 또한 하나의 객체로 바라볼 수 있으므로 객체지향적으로 코드를 작성하는 것이 일반적으로 적합합니다.
PyTorch를 사용하는 많은 개발자는 nn.Module을 이용하여 DL model 개발 중입니다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() <- nn.Module의 init함수 상속
def forward(self, x):
PyTorch는 model 설계에 필요한 까다로운 함수들을 모두 nn.Module Class에 구현해 놓았습니다.
이에 따라 개발자는 model을 설계할 때 nn.Module을 상속받음으로써 까다로운 부분에 대해 신경쓰지 않고
1) model의 network를 초기화할 init 함수
2) input을 model에 feed하여 결과값을 산출하는 forward 함수
만을 고려하면 손쉽게 model을 만들 수 있습니다.
주의해야할 점은 model에 input을 feed할 때 forward함수를 직접 호출하는 것이 아닌 model을 초기화 하고 변수로 설정하셔야 합니다.
model = Net()
out = model.forward(x) # <- don't do ilke this!
out = model(x) # <- it's correct
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2))
self.conv1 = nn.Conv2d(in_channels = 1,
out_channels = 6,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0))
self.conv2 = nn.Conv2d(in_channels = 6,
out_channels = 16,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0))
self.conv3 = nn.Conv2d(in_channels = 16,
out_channels = 120,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0))
self.linear1 = nn.Linear(120, 84)
self.linear2 = nn.Linear(84, 10)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = self.relu(self.conv3(x)) # Nx120x1x1 -> Nx120
x = x.reshape(x.shape[0], -1)
x = self.relu(self.linear1(x))
return self.linear2(x)
image = torch.randn((64, 1, 32, 32))
model = LeNet()
with torch.no_grad():
out = model(image)
out.size()
torch.Size([64, 10])nn.Sequential¶
일반적으로 nn.Module의 경우 전체 모델을 설계할 때 나타냅니다.
하지만 model의 일부 구조가 반복되는 경우 코드 가독성 및 유지보수를 위해 이를 하나의 객체로 묶고 싶어집니다.
이러한 구조를 원할 때 유용하게 nn.Sequential을 이용하면 모델 설계에 도움이 됩니다.
cf) nn.Seuqntial은 layer을 순서대로 설정하고 input을 feed하면 순서에 따라 layer를 적용합니다.
model = nn.Sequential(
nn.Conv2d(in_channels = 1,
out_channels = 6,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0)),
nn.ReLU(),
nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2)),
nn.Conv2d(in_channels = 6,
out_channels = 16,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0)),
nn.ReLU(),
nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2)),
nn.Conv2d(in_channels = 16,
out_channels = 120,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
image= torch.randn(64, 1, 32, 32)
output = model(image)
output.size()
torch.Size([64, 10])nn.Sequntial in nn.Moduel¶
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.c1_s2_block = nn.Sequential(
nn.Conv2d(in_channels = 1,
out_channels = 6,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0)),
nn.ReLU(),
nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2))
)
self.c3_s4_block = nn.Sequential(
nn.Conv2d(in_channels = 6,
out_channels = 16,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0)),
nn.ReLU(),
nn.AvgPool2d(kernel_size = (2,2),
stride = (2,2))
)
self.c5_f6_block = nn.Sequential(
nn.Conv2d(in_channels = 16,
out_channels = 120,
kernel_size = (5, 5),
stride= (1, 1),
padding = (0, 0)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(120, 84),
nn.ReLU(),
)
self.classifier = nn.Linear(84, 10)
def forward(self, x):
x = self.c1_s2_block(x)
x = self.c3_s4_block(x)
x = self.c5_f6_block(x)
x = self.classifier(x)
return x
x= torch.randn(64, 1, 32, 32)
model = LeNet()
with torch.no_grad():
output = model(x)
output.size()
torch.Size([64, 10])'딥러닝 > 딥러닝 모델' 카테고리의 다른 글
| PyTorch로 Transformer 구현하기 (0) | 2022.12.07 |
|---|---|
| PyTorch로 EfficientNet 구현하기 (0) | 2022.12.07 |
| PyTorch로 ResNet 구현하기 (0) | 2022.12.07 |
| PyTorch로 GoogLeNet 구현하기 (0) | 2022.12.07 |
| PyTorch로 VGG network 구현하기 (0) | 2022.12.07 |